Getting Started with datadelivery¶
In order to start using datadelivery to deploy an AWS toolkit for explore public dasets using analytics services, users will need:
- ☁️ AWS account available for use
- 🔑 Programatic access on the account with an
access_key_idand asecret_access_key - ⛏ Terraform installed (version >=1.0)
Two ways to use datadelivery
In fact, there are two ways to use datadelivery and all its features:
- By calling it from another Terraform project (prefered one)
- By cloning the source repo and deploying infrastructure by running the Terraform commands
In this section users will take the chance to precisely look at both usage modes in order to select the one that best suits their needs.
Calling datadelivery Module¶
As stated in the official Terraform documentation:
A module is a container for multiple resources that are used together. You can use modules to create lightweight abstractions, so that you can describe your infrastructure in terms of its architecture, rather than directly in terms of physical objects.
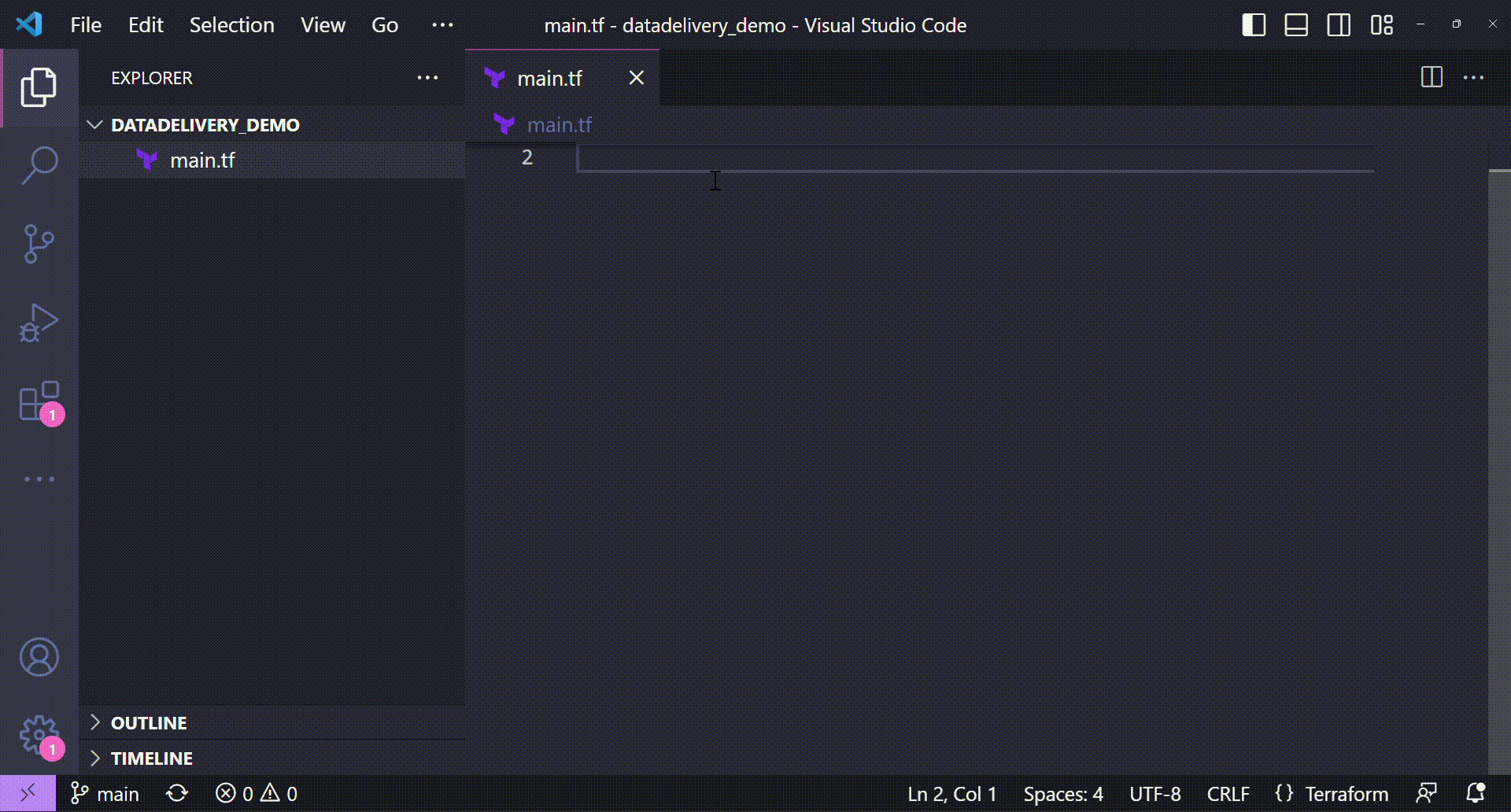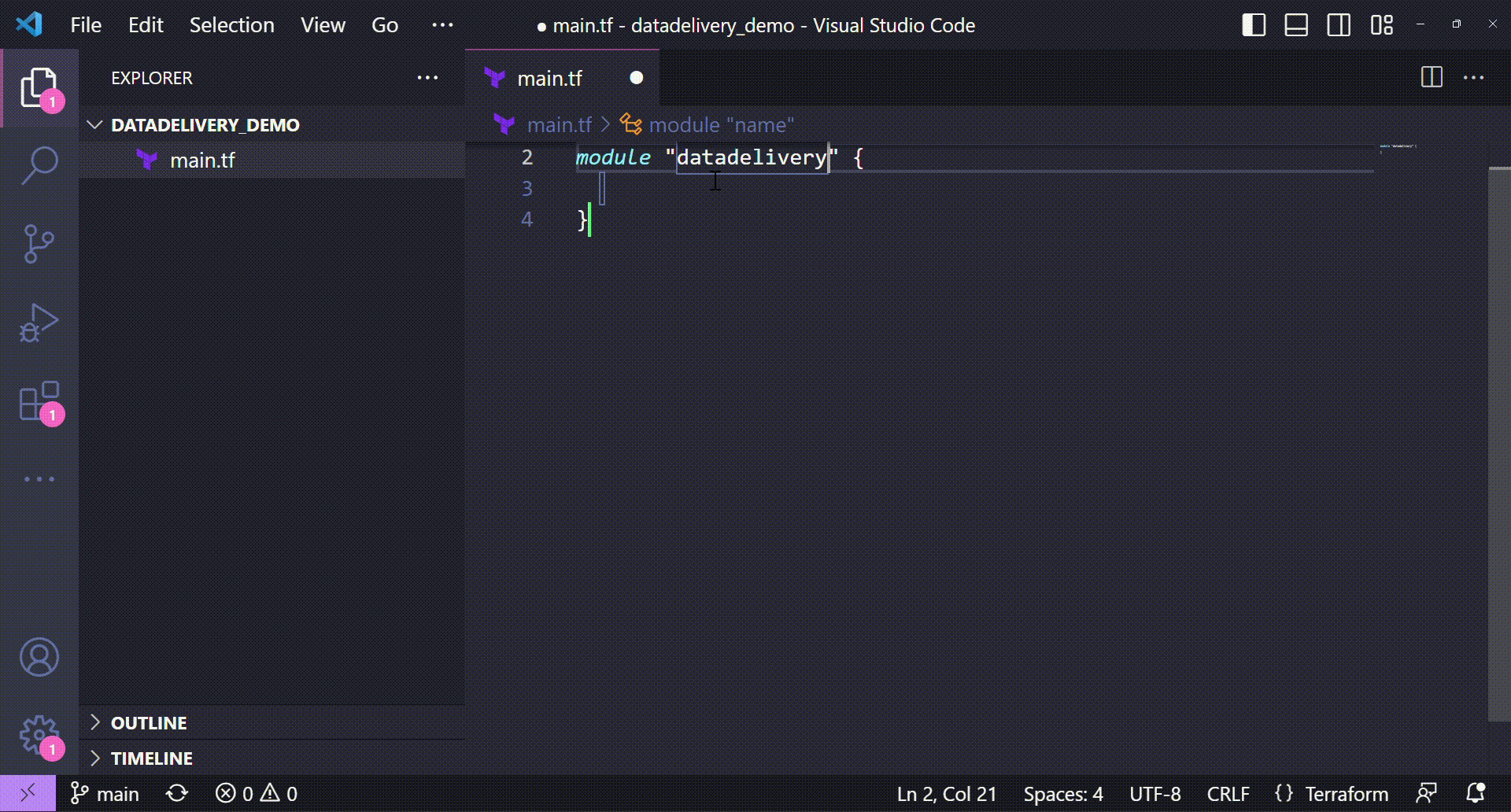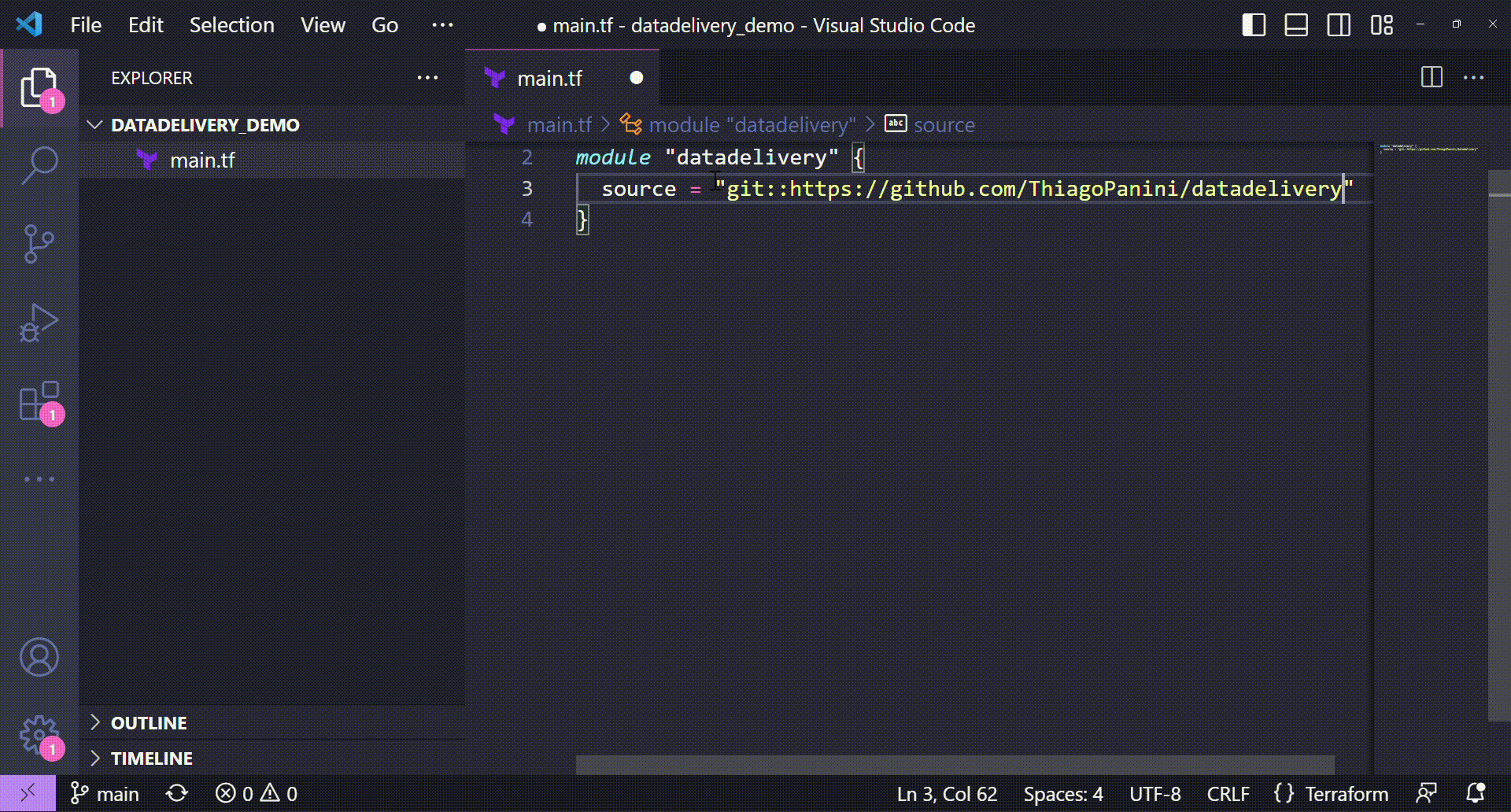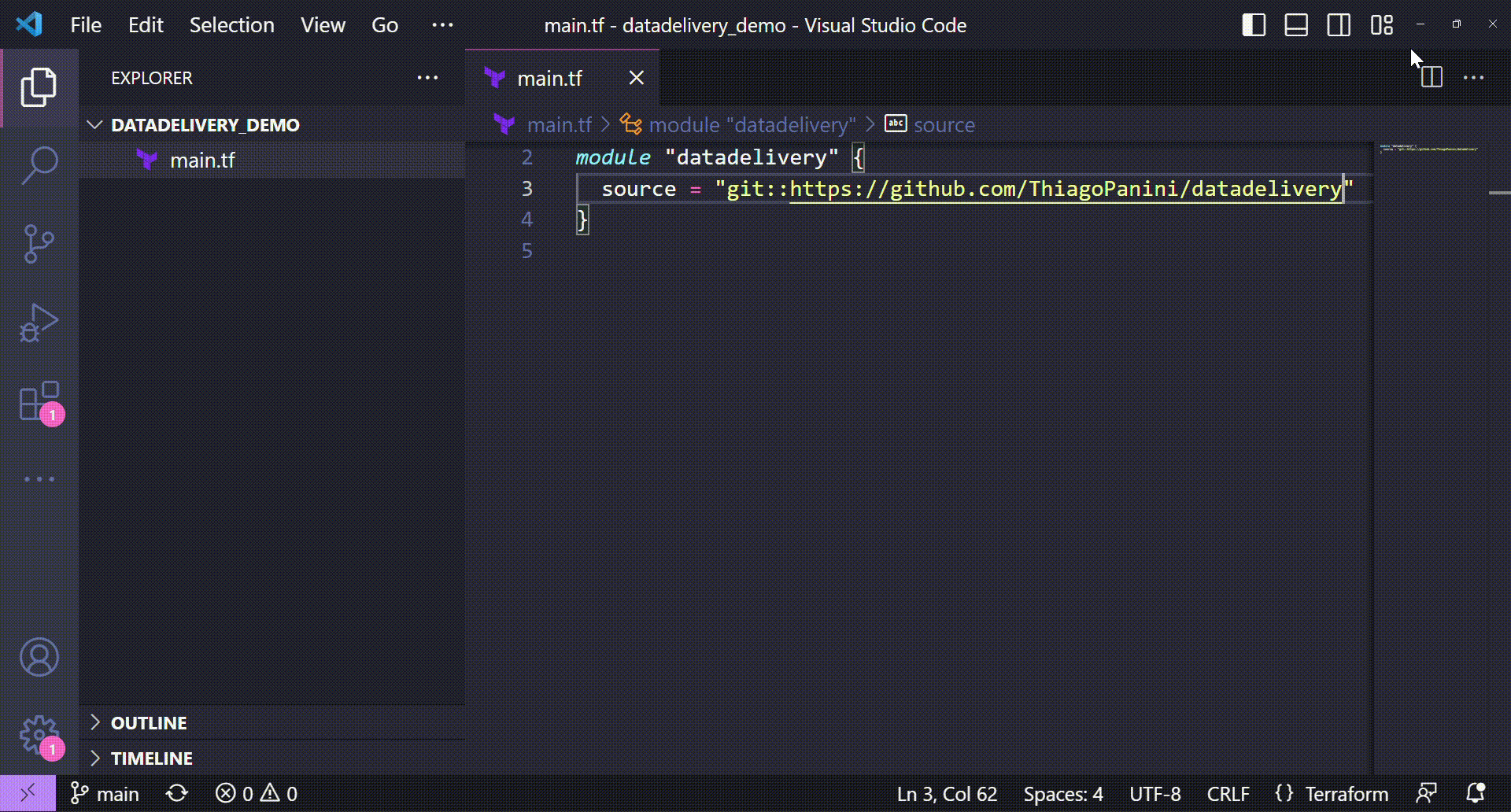
If you already have a Terraform project and you want to add datadelivery features to it, you can just call the module directly from GitHub using the following sintax:
# Calling datadelivery module with default configuration
module "datadelivery" {
source = "git::https://github.com/ThiagoPanini/datadelivery"
}
Do you want to see this in practice? Check out the demos below
The demos consider the simplest Terraform project possible where a main.tf is created to call the datadelivery module. Here you will be able to see a step by step guide on how to declare the module call and to run Terraform commands in order to use datadelivery features in your AWS account.
Creating a Terraform project
There are different ways to use Terraform. In fact, different users can adopt different styles according to their own preferences. The Terraform language documentation will always be a good friend to help users to find their own development style.
Here, to make things simpler, let's just create a new folder and a main.tf file to be our main file of our project root module.
Calling the datadelivery module from GitHub
The next step to have datadelivery features available is to call its module directly from GitHub. It can be defined by a Terraform module call passing the GitHub repository reference as source.
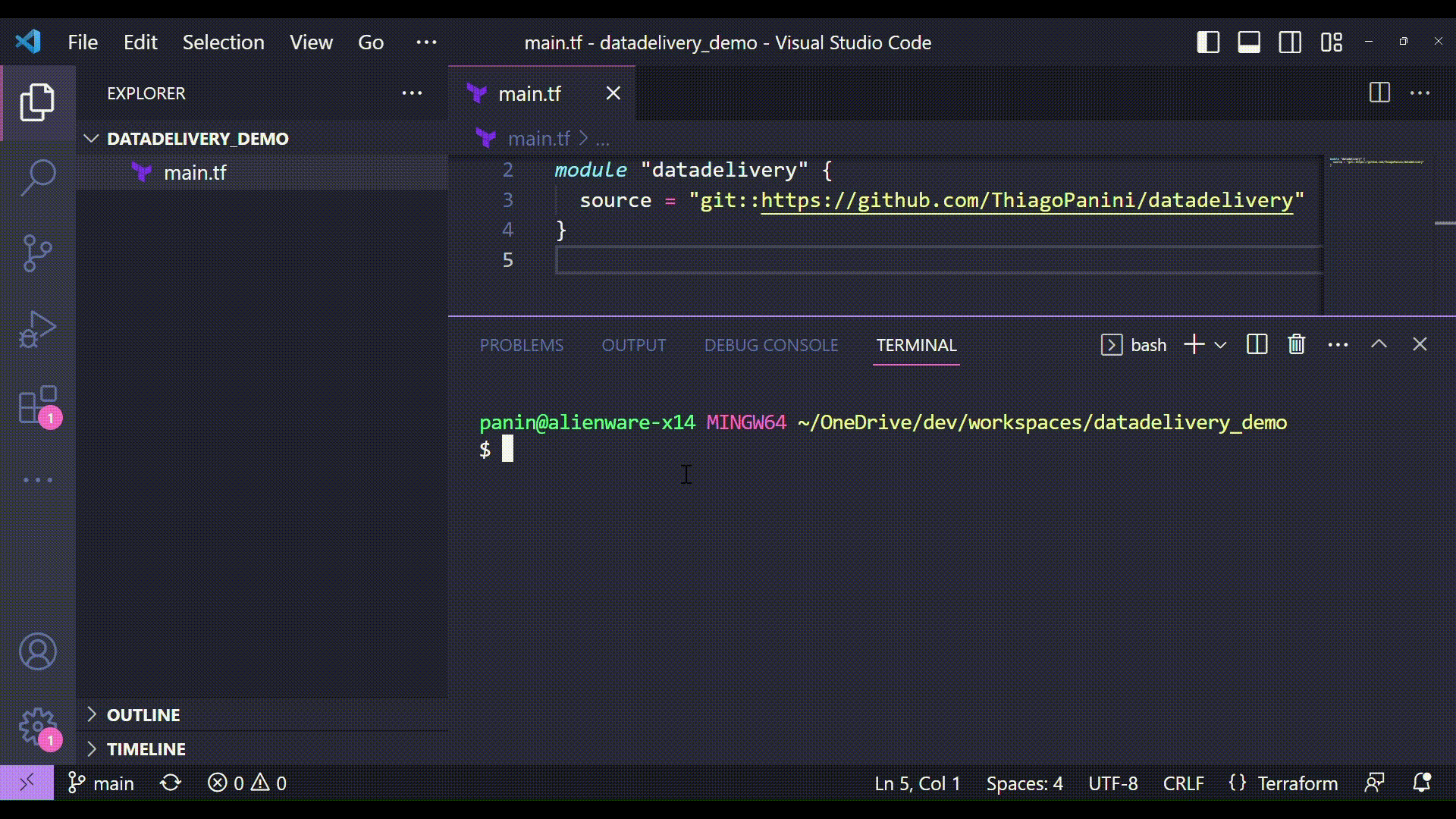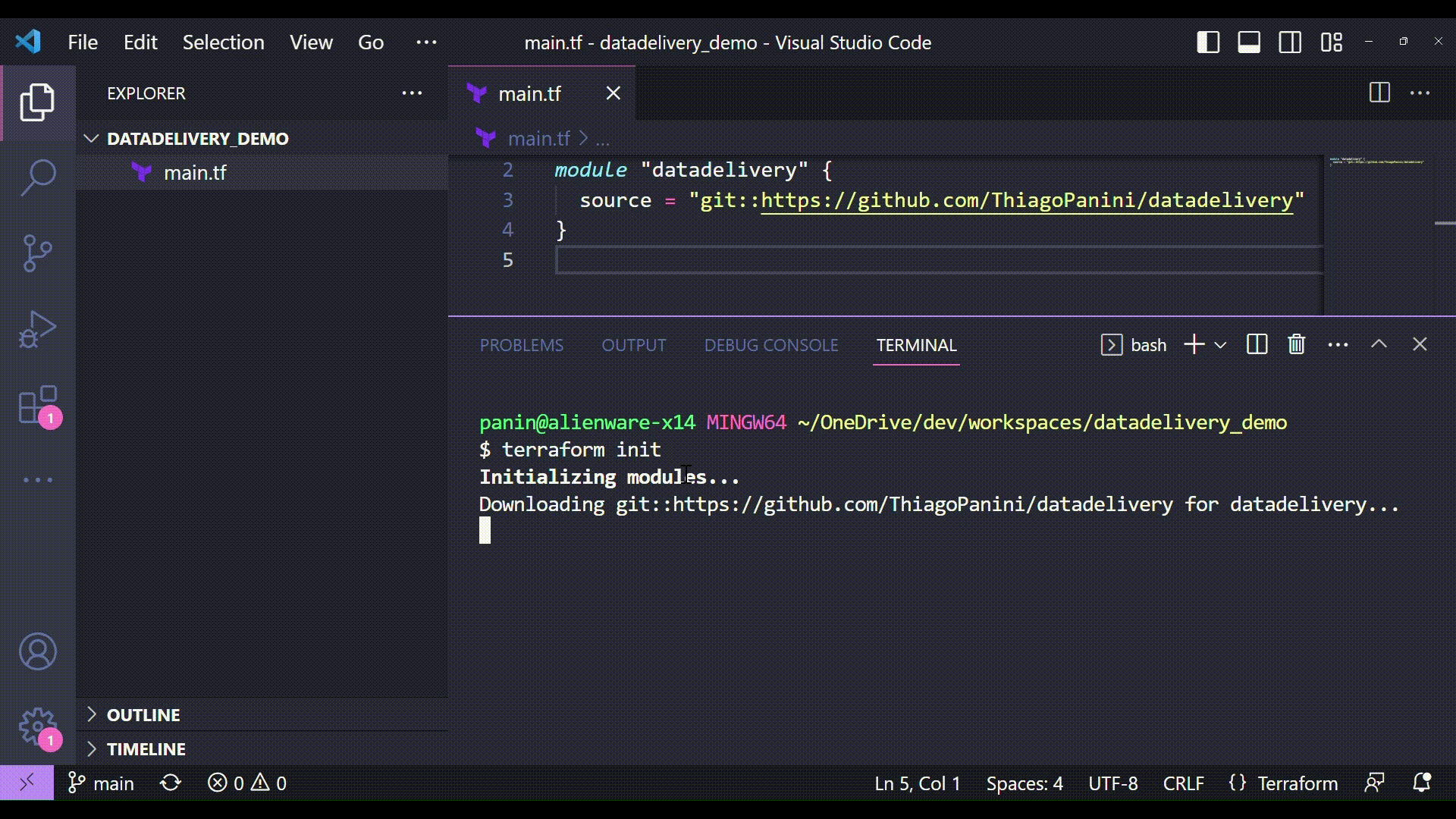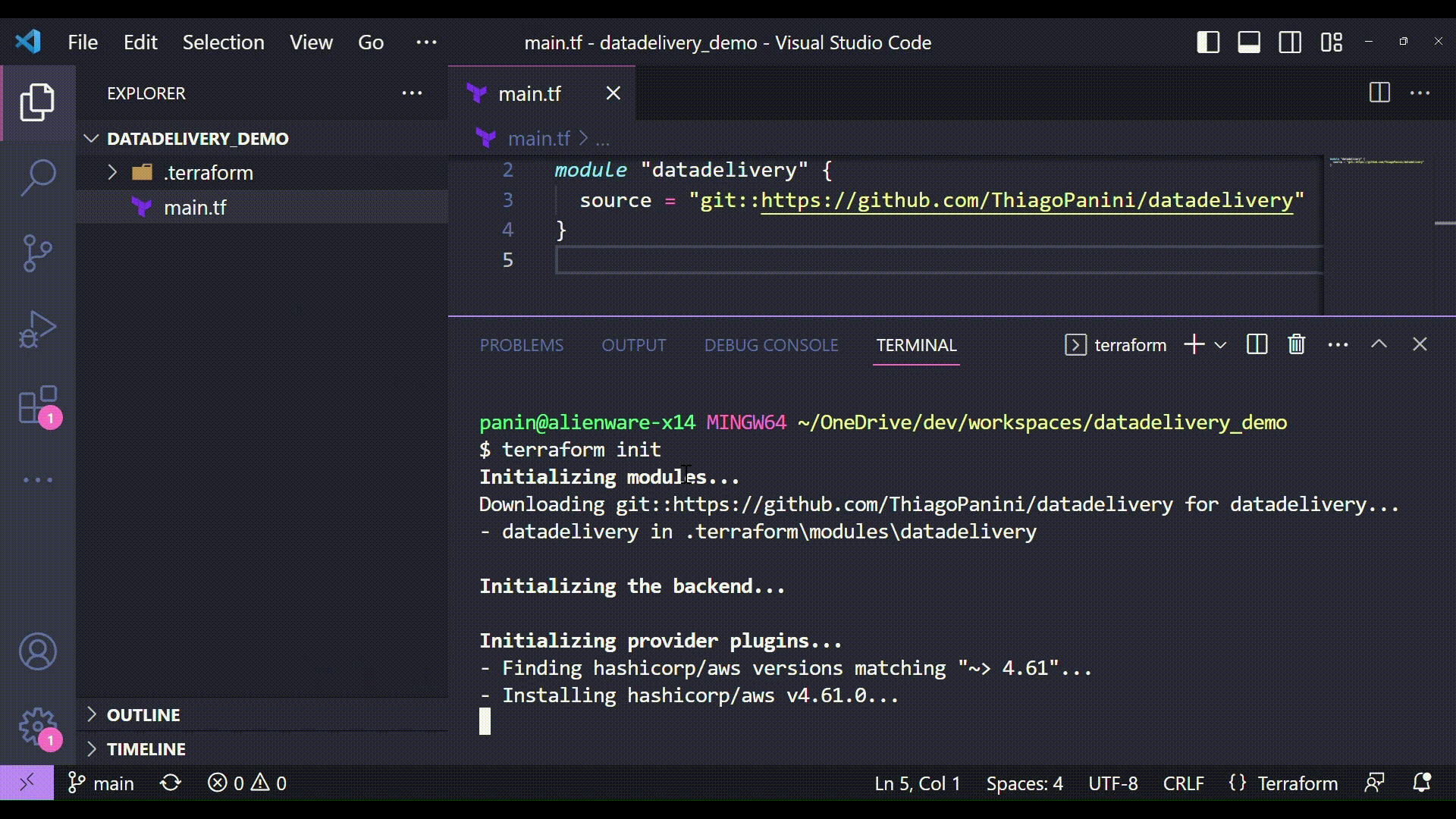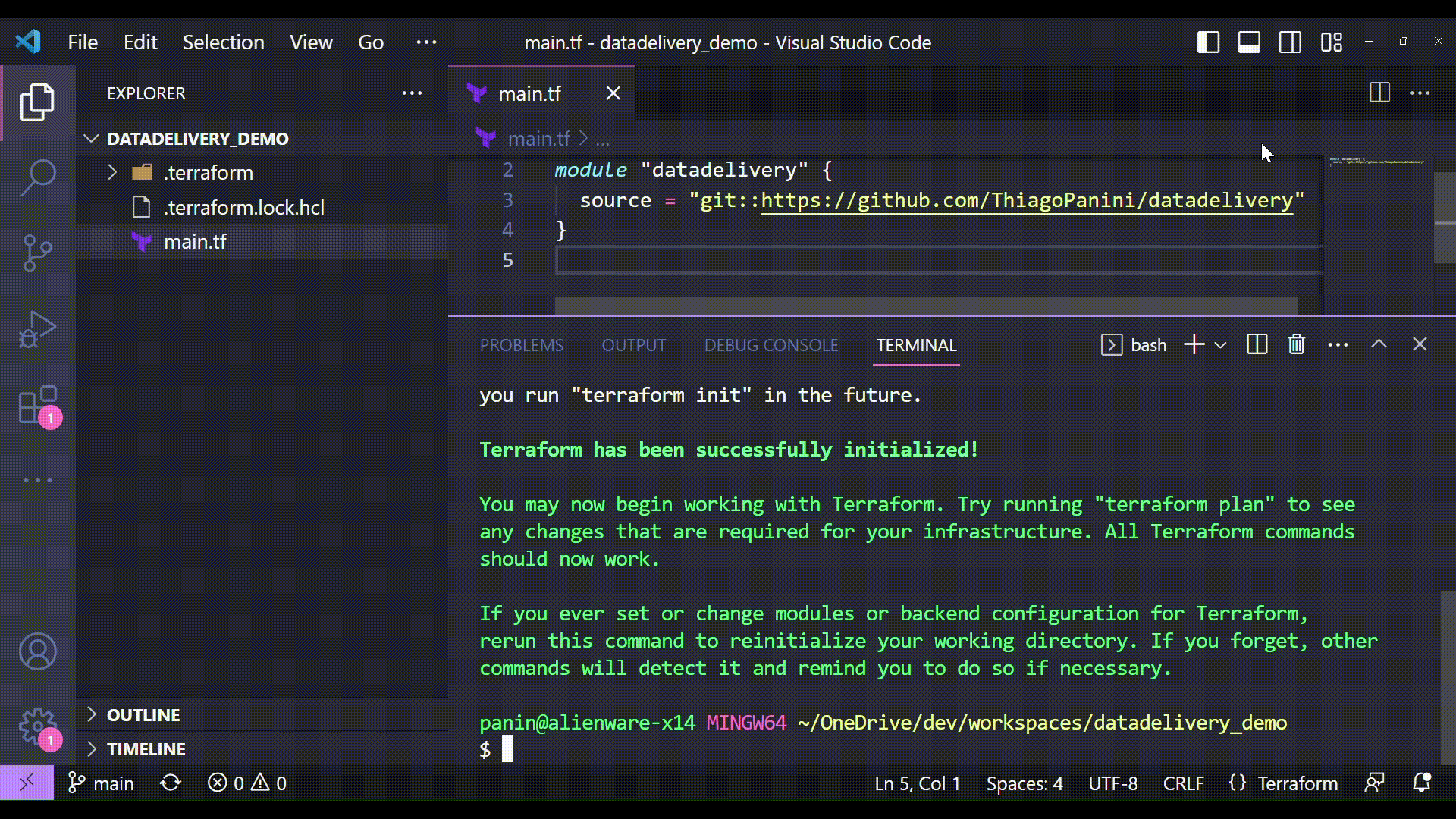
Initializing the module with terraform init
So here we start the Terraform comands to deploy the datadelivery module infrastructure provided. The first one is the command used to initialize the module and install all files needed in the project.
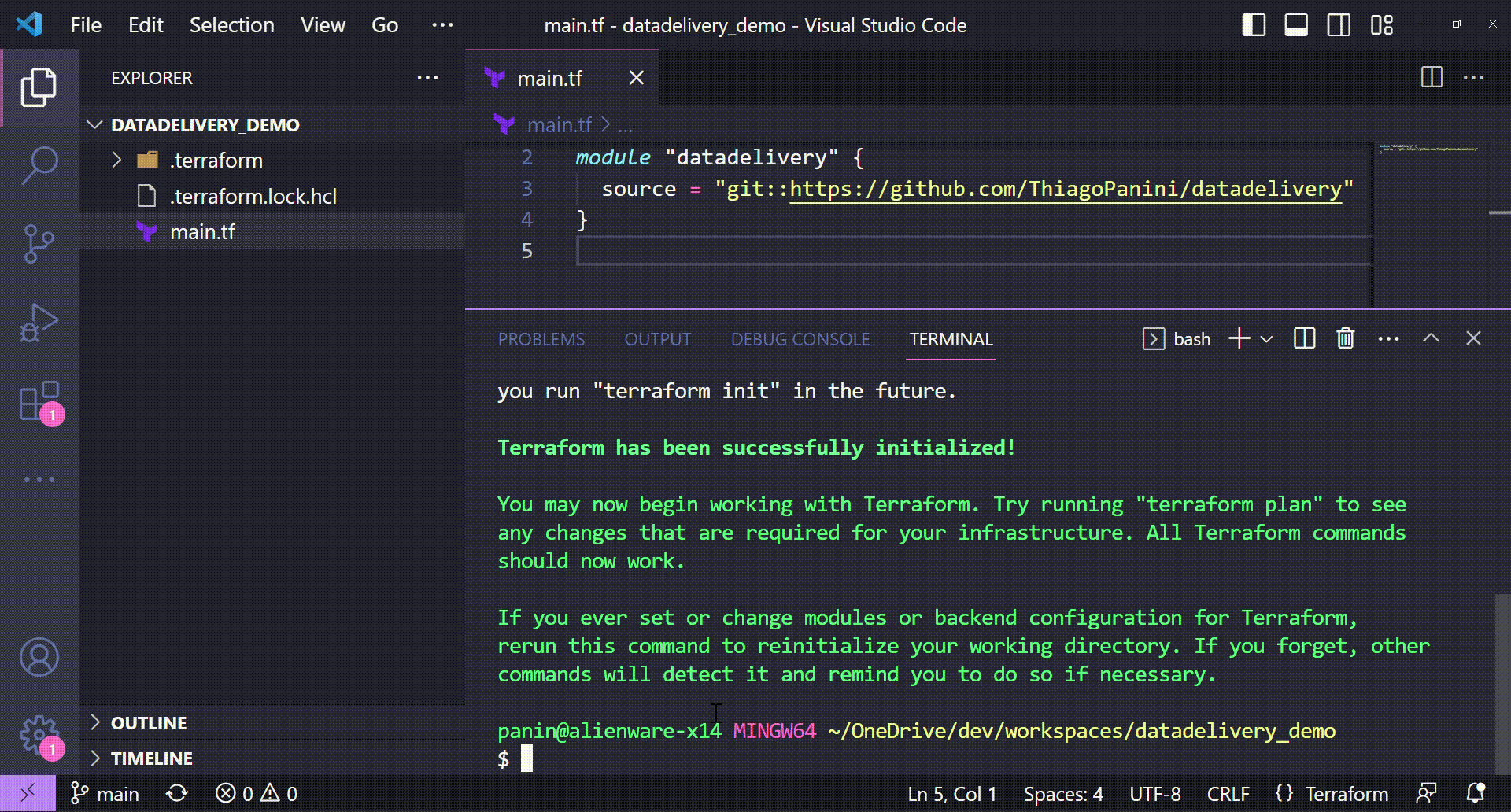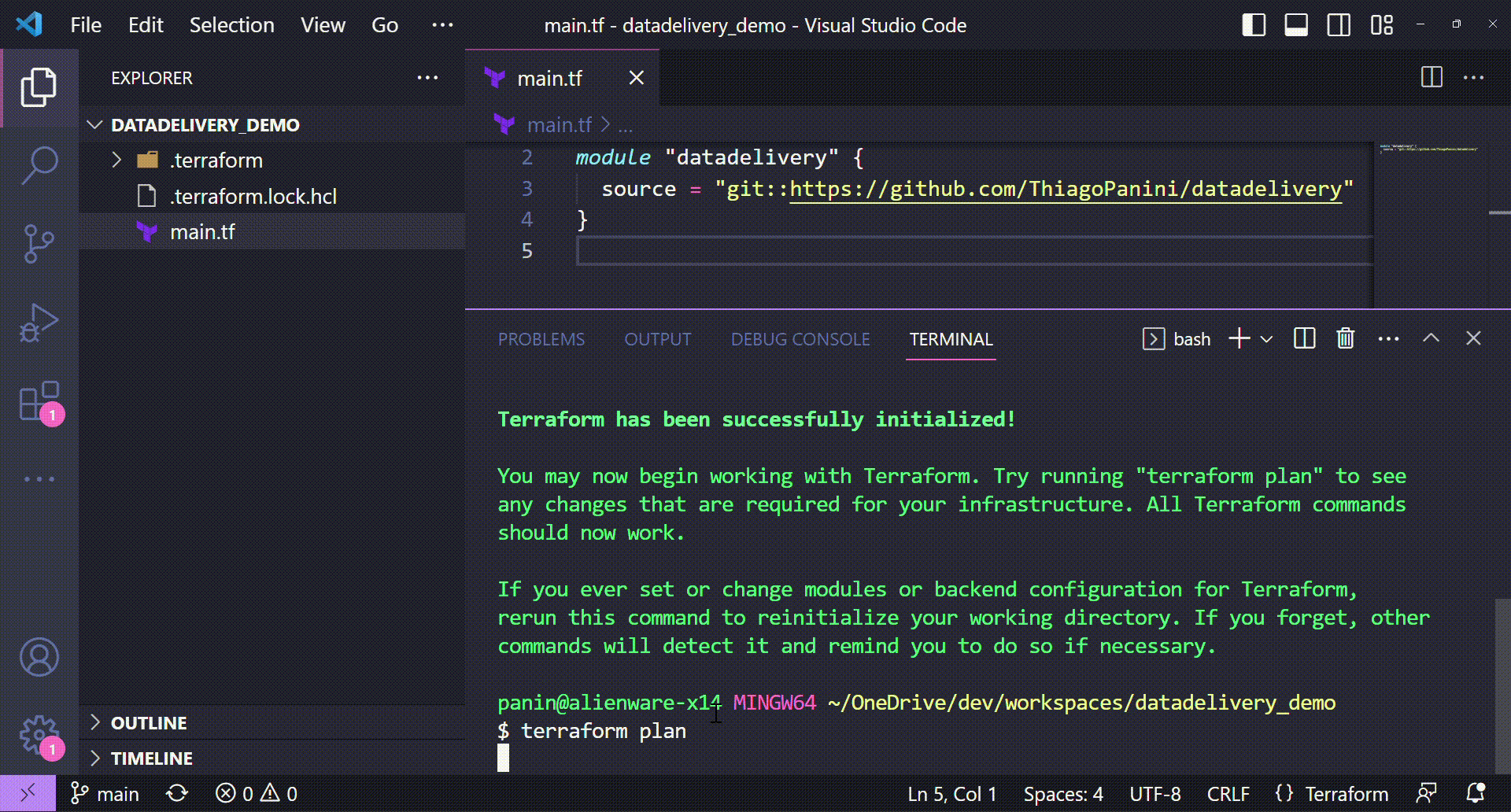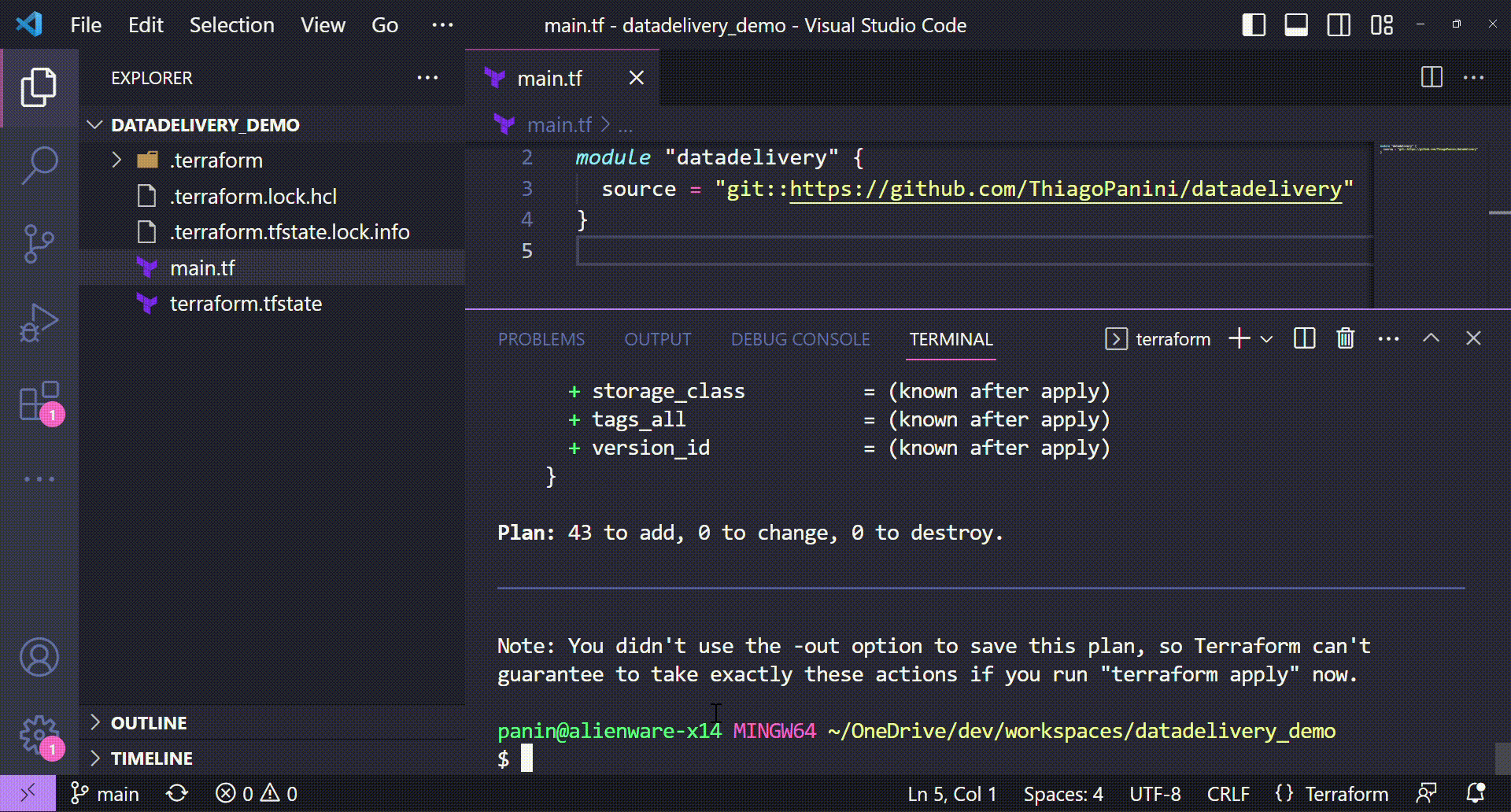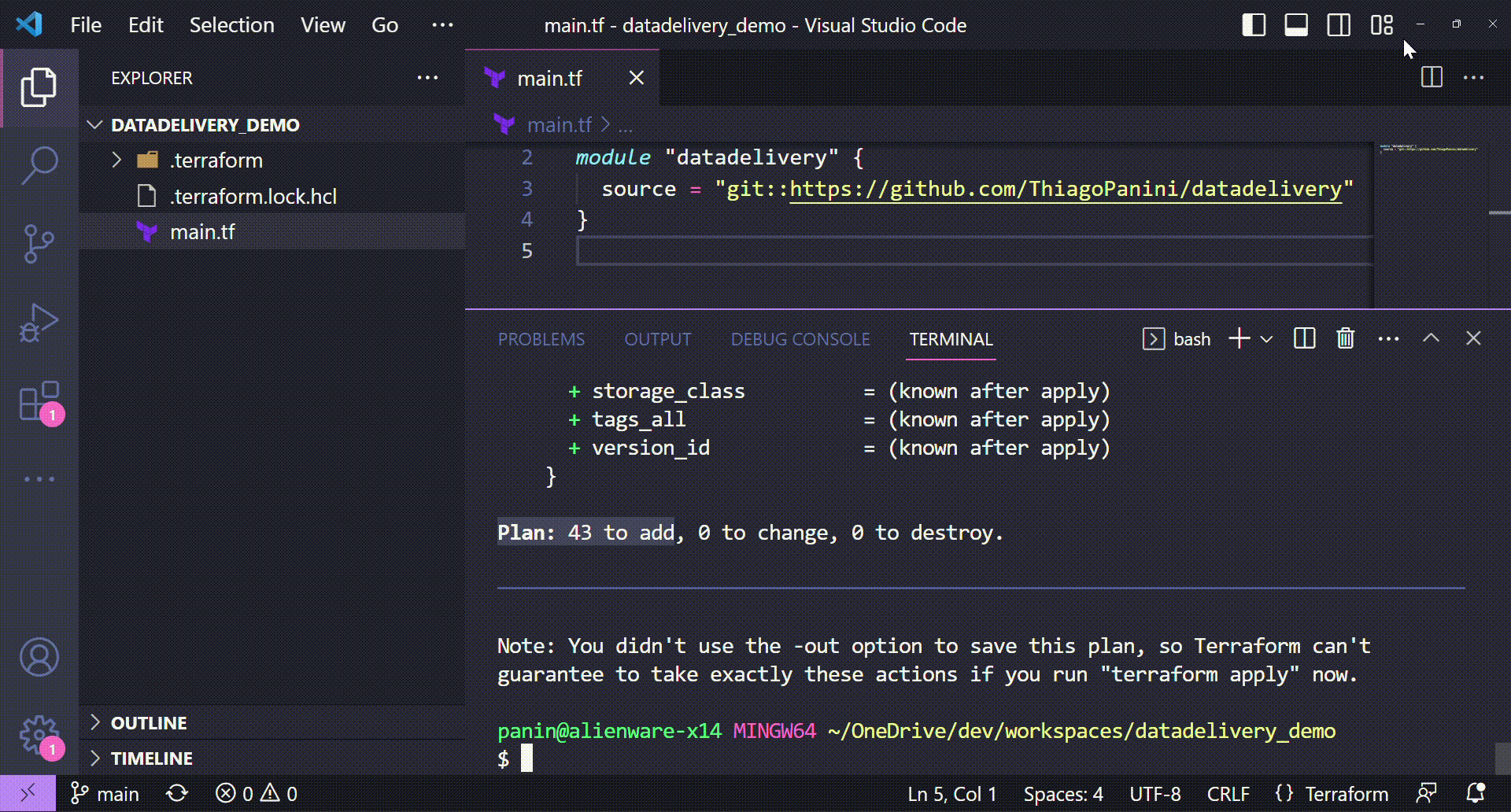
Planning the deploy with terraform deploy
And now that the Terraform project has all components from datadelivery module installed, it's time to see the deployment plan through terraform plan command.
Deploying infrastructure with terraform apply
Finally, we can deploy the infrastructure using the terraform apply command.
Basically, by calling the datadelivery module, users will have a combination of AWS elements created in order to enhance data exploration and analysis. The video below was made to provide a complete view of all resources deployed in the target AWS account after the terraform apply command.

Don't forget to check the Variables section to see all acceptable module variables to customize datadelivery for your need.
Cloning the Source Repo (Optional)¶
Another way to use datadelivery features is by cloning the source GitHub repository in a local environment and running Terraform commands to deploy the infrastructure declared.
This approach considers the following steps:
# 1. Cloning the source repo via HTTPS
git clone https://github.com/ThiagoPanini/datadelivery.git
# 2. Navigating to the local repository
cd datadelivery/
# 3. Initializing Terraform modules
terraform init
# 4. Planning the deploy
terraform plan
# 5. Deploying infra
terraform apply
And that's all to deploy all datadelivery features in your AWS account!
Module Call or Repo Clone?¶
First of all, there is no right or wrong way.
Calling the datadelivery directly from GitHub in a Terraform project can be a good way to decouple things. With this approach, users can do versioning on module call or always get the latest version available. Beyond that, datadelivery can be used in huge Terraform project with another module calls.
Cloning the source GitHub repository and applying the Terraform commands can also be a good alternative if users want to customize the project before deploying. This can be done, for example, by adding new files into data/ folder to be uploaded and hence cataloged by the Glue Crawler. The main trade off is the need to always look at module updates on the source repo or the permanent need to run git pull commands to have the latest features.
Choose whatever fits best for you
As long as you can enjoy using datadelivery to have all you need to start exploring data in AWS, it doesn't matter which way you choose to achieve that.